
인프런의 운영체제 공룡책 강의를 듣고 정리한 포스팅입니다.
CPU 스케줄링
- CPU 스케줄링은 멀티 프로그래밍 운영체제에서 기본
- 멀티 프로그래밍의 목적
- CPU 효율을 극대화
- 여러 프로세스를 동시에 돌릴 수 있음
CPU bound(CPU를 많이 쓰는) 보다 I/O bound가 더 많으면
⇒ 스케줄링을 통한 time sharing이 필요
CPU 스케줄러
CPU 스케줄러는 메모리에 로드된 프로세스 중 누구를 CPU에 할당할 것인지 선택해야 함
⇒ ready 상태에 있는 프로세스 중 선택
프로세스 선택
- ready 상태에 있는 프로세스들 중 선택하기 위해 queue를 만들 필요가 있음
- FIFO Queue : First In, First Out
- Prority Queue : 우선순위가 높은 순으로 결정
선점형 / 비선점형
CPU 스케줄러가 프로세스를
강제로 쫓아내는 것 → 선점형 (Preemtive)
쫓아내지 못하는 것 → 비선점형 (Non-preemptive)
- CPU 스케줄링을 위한 의사 결정
- 프로세스의 상태가 running → waiting
- 프로세스의 상태가 running → ready
- 프로세스의 상태가 waiting → ready
- 프로세스가 종료될 때
- 1, 4번은 비선점형이라 고민할 필요가 없음
- 2, 3번은 비선점이냐, 선점이냐 고민해야 함
디스패처 (Dispatcher)
프로세스한테 CPU를 넘겨주는(컨텍스트 스위치 해주는) 모듈
⇒ CPU 스케쥴러를 통해 프로세스를 선택함
디스패처의 할 일
- 한 프로세스에서 다른 프로세스로 컨텍스트 스위치
- 유저 모드로 바꾸기
- 유저 프로그램의 적당한 위치로 이동시켜 재개해주는 것
디스패처와 CPU 스케줄러의 차이
- CPU 스케줄러는 어떤 프로세스를 선택할지 고르는 것이라면
- 디스패처는 실제로 실행할 프로세스를 바꿔주는 것
디스패치 지연시간 (Dispatch Latency)
- 멈추는 프로세스와 시작하는 프로세스의 컨텍스트 스위치 시간
- 가급적이면 짧아야 함
CPU 스케줄링의 목표
CPU Utilization : CPU를 가장 많이 사용할 수 있도록
Throughput : 단위 시간 내에 프로세스를 끝내는 숫자를 높이게
Turnaround Time : 어떤 프로세스가 도착하고, 실행하고, 종료하기까지의 시간을 최소화
Waiting Time : 어떤 프로세스가 ready queue에서 대기하는 시간을 줄이게
(ready queue의 대기 시간을 합한 것을 최소화)
Response Time : 응답하는 시간을 최소화
CPU 스케줄링 방법
ready queue에 있는 프로세스 중 어떤 프로세스를 CPU 코어에 할당할 것인가
- FCFS (First Come, First Served)
- SJF (Shortest Job First)
- RR (Round Robin)
- Priority based
- MLQ (Multi Level Queue)
- MLFQ (Multi Level Feedback Queue)
FCFS 스케줄링
First Come, First Served
가장 먼저 CPU를 요청한 프로세스한테 CPU 할당
- 가장 간단한 CPU 스케줄링 알고리즘
- FIFO Queue를 이용해 간단하게 구현 가능
- FCFS는 비선점형 알고리즘
- 1개의 CPU bound와 많은 I/O bound 프로세스가 있다면
- CPU를 많이 쓰지 않아도 CPU를 많이 쓰는 프로세스를 기다려야 함
- 콘보이 효과 (Convoy Effect)
- 좋은 효율을 얻을 수 없음
예시
0초에 프로세스 P1, P2, P3가 CPU 할당 요청 했을 때

| waiting time | turnaround time | |
| P1 | 0 | 24 |
| P2 | 24 | 27 |
| P3 | 27 | 30 |
| total | 51 | 81 |
| average | 17 (51/3) | 27 (81/3) |
- 최소화가 안되고, 도착 순서에 따라 많이 달라짐
- CPU burst time에 따라 waiting time과 turnaround time이 달라짐
SJF 스케줄링
Shortest Job First
도착 순서와 무관하게 CPU burst time이 작은 것부터 CPU 할당
- SJF 스케줄링의 구현
- 프로세스의 CPU burst time 기준으로 구현해야 하는데, 해당 프로세스가 얼마만큼 사용할지 알 방법이 없음
- 예측을 통해 근사적으로 구해야 함
- 과거를 통해 예측해 지수적 평균을 내보자
- SJF는 비선점형 알고리즘
- 프로세스 실행 도중에 남은 CPU burst time보다 작은 프로세스가 들어와도 마저 실행시킴
예시
0초에 프로세스 P1, P2, P3, P4가 CPU 할당 요청했을 때,
| Process | Burst Time |
| P1 | 6 |
| P2 | 8 |
| P3 | 7 |
| P4 | 3 |

| waiting time | turnaround time | |
| P1 | 3 | 9 |
| P2 | 16 | 24 |
| P3 | 9 | 16 |
| P4 | 0 | 3 |
| total | 28 | 52 |
| average | 7 (28/4) | 13 (52/4) |
- 최적을 증명할 수 있음
- 평균 waiting time이 최소화
SRTF 스케줄링
Shortest Remaining Time First
남은 CPU burst time이 작은 것부터 CPU 할당
- 선점형 방식의 SJF 스케줄링
- 실행 중인 프로세스의 남은 CPU burst time보다 새로 들어온 프로세스의 시간이 짧으면 선점시켜서 바꿔버림
예시
| Process | Arrival Time | Burst Time |
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |

| waiting time | |
| P1 | 9 (10-1) |
| P2 | 0 (1-1) |
| P3 | 15 (17-2) |
| P4 | 2 (5-3) |
| total | 26 |
| average | 6.5 (26/4) |
RR 스케줄링
Round Robin
일정한 시간(time quantum) 간격으로 나누어 CPU 할당 (시분할)
- time quantum을 가지는 선점형 방식의 FCFS
- 프로세스의 CPU burst time이 time quantum보다 크면 CPU를 뺏고, ready queue의 맨 끝에 들어가 CPU를 다시 획득할 때까지 대기함
- time quantum(time slice)
- RR 스케줄링 알고리즘은 time quantum을 얼마나 주느냐에 따라 성능이 달라짐
- 짧아질수록 컨텍스트 스위치가 많이 일어남 ⇒ 디스패치 레이턴시
- 길어지면 FCFS와 같게 됨
- ready queue의 구현
- circular queue
예시
| Process | Burst Time |
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |

| time quantum = 4 | waiting time |
| P1 | 6 |
| P2 | 4 |
| P3 | 7 |
| total | 17 |
| average | 5.66 (17/3) |
- RR 스케줄링에서 평균 waiting time은 길어질 수 있음
Priority-base 스케줄링
프로세스의 우선순위가 높은 순으로 CPU 할당
- 같은 우선순위면 FCFS 순으로 (먼저 온 순서대로)
- 다음 CPU burst time이 작은 순으로 우선순위 기반 스케줄링
- 선점형이면 SRTF, 비선점형이면 SJF
- 기아 문제 (starvation, indefinite blocking)
- 우선순위가 낮은 것은 대기하고 있는데, 우선순위가 높은 것들이 계속 들어와서 CPU를 선점 못하는 문제
- 해결 방법 : aging (나이 먹기)
- 기다릴수록 우선순위를 높여주자
- RR과 우선순위 스케줄링의 결합
- 우선순위가 높은 프로세스부터 처리하되, 우선순위가 같은 프로세스들은 RR 스케줄링으로
예시
우선순위가 높을수록 숫자가 낮음
| Process | Burst Time | Priority |
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 4 |
| P4 | 1 | 5 |
| P5 | 5 | 2 |

예시 (RR과 우선순위 스케줄링의 결합)
time quantum = 2
| Process | Burst Time | Priority |
| P1 | 4 | 3 |
| P2 | 5 | 2 |
| P3 | 8 | 2 |
| P4 | 7 | 1 |
| P5 | 3 | 3 |

MLQ 스케줄링
Multi Level Queue
각각의 우선순위마다 ready queue를 따로 두고,
우선순위가 높은 ready queue에 있는 프로세스들을 처리한 뒤, 다음 ready queue의 프로세스 처리
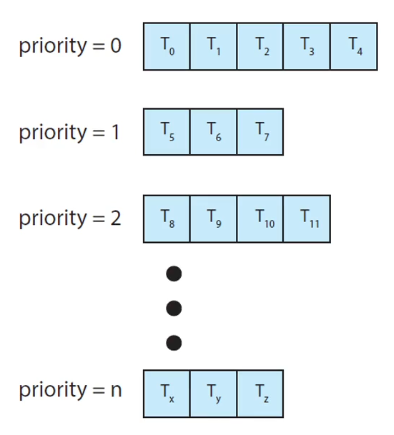
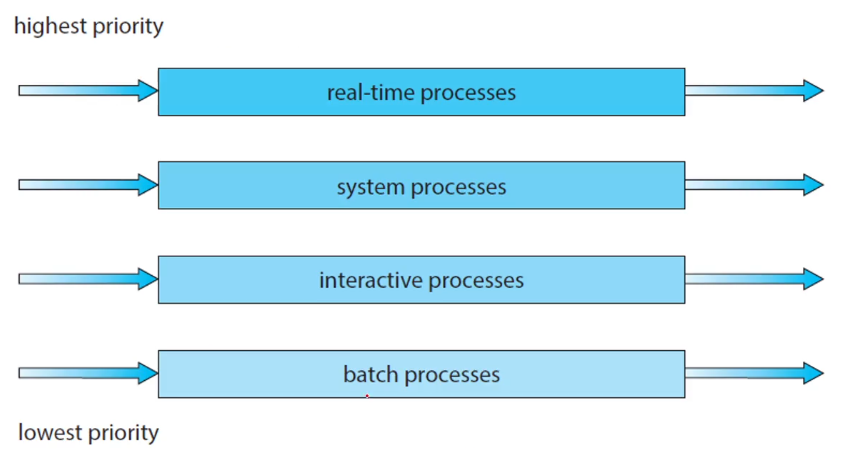
- 우선순위가 낮은 ready queue에 있는 프로세스들이 실행이 안될 수 있음
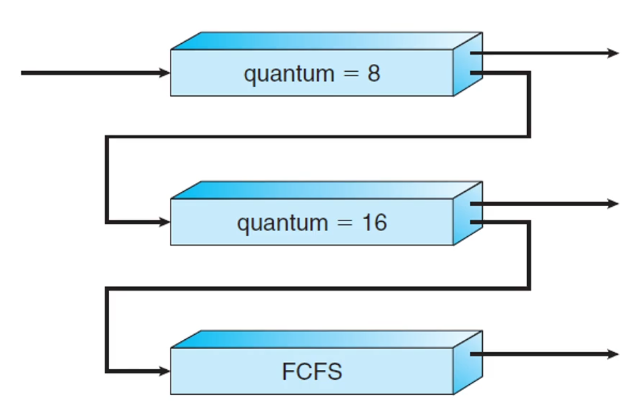
- 그래서 등장한 것이 MLFQ(Multi Level Feedback Queue)
- time quantum을 늘려가며 처리
- 실제 운영체제의 CPU 스케줄링 알고리즘
스레드 스케줄링
- 현대적 컴퓨터에선 스레드를 지원하기 때문에 프로세스 스케줄링을 안함
- 대신에 스레드 스케줄링을 함
- 스레드의 종류에는 커널 스레드와 유저 스레드가 있음
- 운영체제가 스케줄링하는 스레드 → 커널 스레드
- 유저 스레드는 스레드 라이브러리가 관리함,
커널 스레드에 맵핑만 해주면 됨
실시간 운영체제의 스케줄링
주어진 시간 내에 어떤 작업을 완료할 수 있어야 함
- soft realtime
- 크리티컬한 실시간 프로세스가 반드시 그 시간 내에 완성되지는 않지만,
크리티컬하지 않은 프로세스보다는 빠르게 실행되도록 보장 - ex) 전화하는 상황에서 데이터를 음성으로 처리하는 경우 (놓쳐도 좀 괜찮기 때문)
- 크리티컬한 실시간 프로세스가 반드시 그 시간 내에 완성되지는 않지만,
- hard realtime
- 어떤 작업이 반드시 deadline 내에 완료되어야 함
- ex) 로켓 탐사선 궤도 계산
- 우선순위 스케줄링을 통해 처리